Extracting data from Goethe Zertifikat B1 Wortliste pdf
Problem statement
I’m in the process of learning German1. And I think flashcards are the best thing ever.
Unfortunately the canonical German B1 vocabulary comes in the form of a gnarly PDF with four-column layout.
I would like that in a more sane form, so I can easily import it into my flashcard program.
This post details the journey to get there.
Spoiler alert: If you just want the resulting list, it’s linked in the Solution section. You’re welcome.
Detailed problem statement
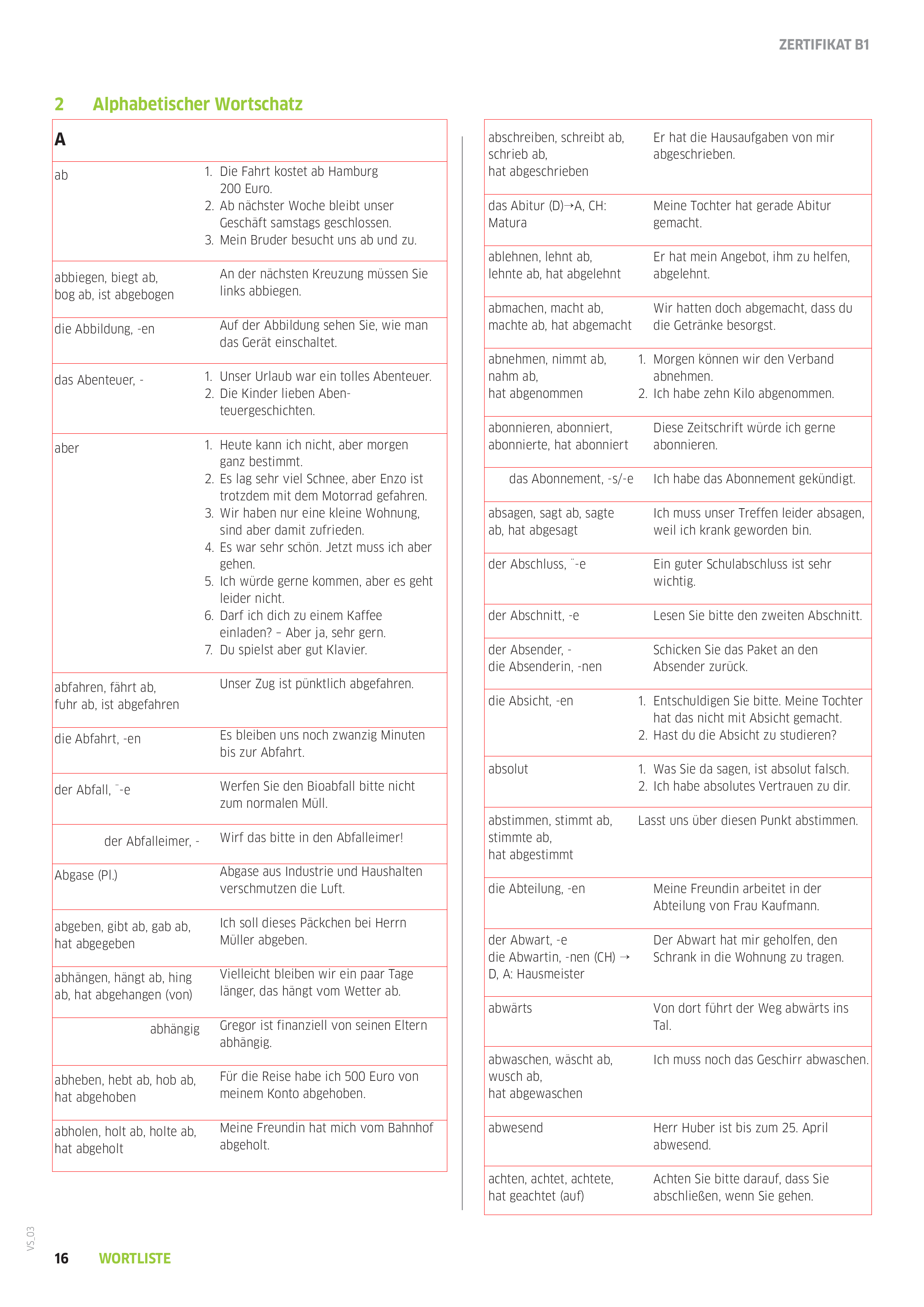
For the rest of you, let me take you on a “diff driven development”2 journey to take a PDF whose pages look like this:
 Example text from Goethe-Zertifikat_B1_Wortliste.pdf, page 16
Example text from Goethe-Zertifikat_B1_Wortliste.pdf, page 16
and turn it into text:
| Word | Example |
|---|---|
| ab | 1. Die Fahrt kostet ab Hamburg 200 Euro. 2. Ab nächster Woche bleibt unser Geschäft samstags geschlossen. 3. Mein Bruder besucht uns ab und zu. |
| abbiegen, biegt ab, bog ab, ist abgebogen | An der nächsten Kreuzung müssen Sie links abbiegen. |
| die Abbildung, -en | Auf der Abbildung sehen Sie, wie man das Gerät einschaltet. |
| abschreiben, schreibt ab, schrieb ab, hat abgeschrieben | Er hat die Hausaufgaben von mir abgeschrieben. |
| das Abitur (D) → A, CH: Matura |
Meine Tochter hat gerade Abitur gemacht. |
| ablehnen, lehnt ab, lehnte ab, hat abgelehnt | Er hat mein Angebot, ihm zu helfen, abgelehnt. |
| abmachen, macht ab, machte ab, hat abgemacht | Wir hatten doch abgemacht, dass du die Getränke besorgst. |
The final form of the text doesn’t matter that much, HTML table is fine. As long as it can be imported into the Flashcards Deluxe program I’m using for flashcards.
Road to solution
First, I looked to see if someone else had done it. Unfortunately, I couldn’t find that.3
But, since I’m familiar with both pdftotext and tesseract (OSS OCR engine),
I thought this must be easy. And normally, yes. Not so with this pdf:
$ pdftotext -f 16 -l 16 Goethe-Zertifikat_B1_Wortliste.pdf - | head -n 20
ZERTIFIKAT B1
2
Alphabetischer Wortschatz
A
1. Die Fahrt kostet ab Hamburg
200 Euro.
2. Ab nächster Woche bleibt unser
Geschäft samstags geschlossen.
3. Mein Bruder besucht uns ab und zu.
ab
abbiegen, biegt ab,
bog ab, ist abgebogen
An der nächsten Kreuzung müssen Sie
links abbiegen.
If you look closely, the ab follows its own example. Oh boy.
So, bright idea! I can cut up an individual page into columns, and then process each column!
Figuring out where the column boundaries are
In order to figure out the columns, I settled on exporting the pages to pdf, and then merging them one over the other:
pdftocairo -png -r 300 Goethe-Zertifikat_B1_Wortliste.pdf
IMG_SIZE=$(identify Goethe-Zertifikat_B1_Wortliste-*png | \
awk '{print $3}' | sort -u)
convert -size $IMG_SIZE xc:white boundaries.png
# pages 16 - 102 are interesting (to me)
for i in $(seq -w 16 102); do
convert boundaries.png G*$i*.png -compose darken -composite boundaries.png
done
By starting with all-white image and using -compose darken, I’m
darkening down the resulting image – thus getting the boundaries clearly
visible:
 column boundaries (click for full version)
column boundaries (click for full version)
A little bit of mucking around in gimp (with the Guide tool):
 (… snip …)
column cuts using Guides (click for full version)
(… snip …)
column cuts using Guides (click for full version)
gets me the correct coordinates (for 300 dpi):
| coord | from | to |
|---|---|---|
| y | 320 | 3260 |
| column 1 | 140 | 540 |
| column 2 | 540 | 1200 |
| column 3 | 1300 | 1710 |
| column 4 | 1710 | 2340 |
So I’ll just OCR the crap out of the individual columns
So I went ahead thinking that I might OCR the way out of it after all:
# Let's cut up page 16 ...
for i in 016; do
convert G*$i.png -crop $[540-140]x$[3260-320]+140+320 $i-c1.png
convert G*$i.png -crop $[1200-540]x$[3260-320]+540+320 $i-c2.png
convert G*$i.png -crop $[1710-1300]x$[3260-320]+1300+320 $i-c3.png
convert G*$i.png -crop $[2340-1710]x$[3260-320]+1710+320 $i-c4.png
done
But when it came to the actual OCRing:
# Column 1
$ tesseract -l deu 016-c1.png - | head -n 5
abbiegen, biegt ab,
bog ab, ist abgebogen
die Abbildung, -en
# Column 2
$ tesseract -l deu 016-c2.png - | head -n 5
. Die Fahrt kostet ab Hamburg
200 Euro.
. Ab nächster Woche bleibt unser
Geschäft samstags geschlossen.
# Column 3
$ tesseract -l deu 016-c3.png - | head -n 5
abschreiben, schreibt ab,
schrieb ab,
hat abgeschrieben
das Abitur (DJ)>A, CH:
# Column 4
$ tesseract -l deu 016-c4.png - | head -n 5
Er hat die Hausaufgaben von mir
abgeschrieben.
Meine Tochter hat gerade Abitur
gemacht.
There were all kinds of problems:
- Column 1 is missing
Aandab - Column 2 is missing numbers
- Column 3 has
(DJ)>Ainstead of(D)→A
I mean, see the full page 16 and the associated cuts (col 1, col 2, col 3, col 4) for comparison.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
So, this sort of result won’t do.
Fine, I’ll pdftotext the individual columns
# Column 1
$ pdftotext -f 16 -l 16 -r 300 -x 140 -y 320 -W $[540-140] -H $[3260-320] \
Goethe-Zertifikat_B1_Wortliste.pdf - | head -n 5
A
ab
abbiegen, biegt ab,
bog ab, ist abgebogen
# Column 2
$ pdftotext -f 16 -l 16 -r 300 -x 540 -y 320 -W $[1200-540] -H $[3260-320] \
Goethe-Zertifikat_B1_Wortliste.pdf - | head -n 5
1. Die Fahrt kostet ab Hamburg
200 Euro.
2. Ab nächster Woche bleibt unser
Geschäft samstags geschlossen.
3. Mein Bruder besucht uns ab und zu.
# Column 3
$ pdftotext -f 16 -l 16 -r 300 -x 1300 -y 320 -W $[1710-1300] -H $[3260-320] \
Goethe-Zertifikat_B1_Wortliste.pdf - | head -n 5
abschreiben, schreibt ab,
schrieb ab,
hat abgeschrieben
das Abitur (D)→A, CH:
Matura
# Column 4
$ pdftotext -f 16 -l 16 -r 300 -x 1710 -y 320 -W $[2340-1710] -H $[3260-320] \
Goethe-Zertifikat_B1_Wortliste.pdf - | head -n 5
Er hat die Hausaufgaben von mir
abgeschrieben.
Meine Tochter hat gerade Abitur
gemacht.
And oh boy, that’s so much better! See the full dumps (col 1, col 2, col 3, col 4) if curious.
Only “one” problem – how does one split up what’s the definition and examples?
Fine, I’ll detect longer whitespace across c1+c2 and c3+c4
So, the idea is simple – the individual entries are split up whenever there’s long-ish whitespace in both definition and example columns.
How was I going to do that? No, fuck machine learning. XPM and Ruby, obviously.
So let’s convert the appropriate sections to XPM and extract the breaks:
# which page?
P=016
# columns 1 + 2
convert Goethe-Zertifikat_B1_Wortliste-$P.png \
-crop $[1200-140]x$[3260-320]+140+320 $P-l.xpm
ruby detect-breaks.rb $P-l.xpm > $P-l.txt
# columns 3 + 4
convert Goethe-Zertifikat_B1_Wortliste-$P.png \
-crop $[2340-1300]x$[3260-320]+1300+320 $P-r.xpm
ruby detect-breaks.rb $P-r.xpm > $P-r.txt
Let’s look at the magical detect-breaks.rb together, shall we?
#!/usr/bin/env ruby
require 'set'
# How many empty lines does there have to be?
THRESHOLD = 42
# Is this pixels section of the file?
pixels = false
# What is the code for white?
white = nil
# What's the current Y coord of the pixel?
y = 0
# What's the state of our scan?
state = :trail
# Y coord of current start of empty lines
start = nil
# Start of the current rectangle
rect_start = 0
# Overrides
breaks = Hash.new { |h,k| h[k] = Set.new(); h[k] }
# spoiler alert, this will be important later:
#breaks['090-l'] = Set.new([486, 574, 715])
pfx = File.basename(ARGV.first, '.xpm')
File.readlines(ARGV.first).each do |l|
# not in "pixels" section yet?
if !pixels
if l =~ /"(\w+)\s+c\s+white"/
white = $1
end
if l =~ /^\/\*\s+pixels\s+\*\/$/
pixels = true
next
end
end
# we only want pixels here ...
next unless pixels
# skip trailing line
break if pixels && l =~ /^};/
# is the line empty?
empty = l =~ /^"(#{white})+",?$/
# is there an override?
if breaks[pfx].include?(y)
state = :overriden
start = 0
end
# teh state machine
case state
when :trail
state = :look if !empty
when :look
if empty
state = :found
start = y
end
when :found, :overriden
if empty
if y > start + THRESHOLD
puts [rect_start, y].join(' ')
rect_start = y
state = :trail
end
else
state = :look
end
end
y += 1
end
# final summation...
puts [rect_start, y].join(' ') unless state == :trail
And the beautiful result for page 16 is:
$ cat 016-l.txt
0 113
113 380
380 532
532 655
655 843
843 1485
1485 1632
1632 1755
1755 1892
1892 1998
1998 2121
2121 2274
2274 2411
2411 2539
2539 2686
2686 2824
$ cat 016-r.txt
0 201
201 339
339 476
476 614
614 797
797 934
934 1026
1026 1164
1164 1301
1301 1392
1392 1529
1529 1709
1709 1846
1846 2035
2035 2172
2172 2354
2354 2488
2488 2676
2676 2809
2809 2940
Now, don’t tell me you can’t judge the correctness?! What are you, human?
So, yeah, I can’t either, let’s annotate the breaks, shall we:
# page
P=016
# take the png from pdftocairo... and annotate:
cp Goethe-Zertifikat_B1_Wortliste-$P.png $P-annot.png
cat $P-l.txt | ruby annotate.rb $P-annot.png 140 1200 320
cat $P-r.txt | ruby annotate.rb $P-annot.png 1300 2340 320
So together with annotate.rb (which just draws a bunch of rectangles in
the specified places):
#!/usr/bin/env ruby
if ARGV.size != 4
STDERR.puts "Usage: #{File.basename($0)} <f> <x0> <x1> <y>"
exit 1
end
f = ARGV.first
x0, x1, y = *ARGV[1,3].map(&:to_i)
coords = []
STDIN.each do |ln|
coords << ln.split(/\s+/,2).map(&:to_i)
end
cmd = ["convert", f, "-fill", "transparent", "-stroke", "red"]
for y0, y1 in coords
cmd += ["-draw", "rectangle #{x0},#{y+y0} #{x1},#{y+y1}"]
end
cmd << f
system *cmd
we get something readable:
 annotated rectangles (click for full version)
annotated rectangles (click for full version)
I’m almost done… I’ll just extract it now
OK, we have rectangles, let’s extract the texts:
F=Goethe-Zertifikat_B1_Wortliste.pdf
P=016
# Left side
ruby extract.rb "$F" $P $P-l.txt 140 540 1200 320 l
# Right side
ruby extract.rb "$F" $P $P-r.txt 1300 1710 2340 320 r
Obviously the interesting part is the extract.rb where the “magic”
happens:
#!/usr/bin/env ruby
if ARGV.size != 8
STDERR.puts "Usage: #{File.basename($0)} <pdf> <page> <yranges> <x0> <x1> <x2> <y> <col>"
exit 1
end
pdf = ARGV.first
page = ARGV[1]
coords = []
File.readlines(ARGV[2]).each do |ln|
coords << ln.split(/\s+/,2).map(&:to_i)
end
x0, x1, x2, y = ARGV[3,4].map(&:to_i)
col = ARGV[7]
outfile = "#{page}-#{col}.msh"
exit 0 if FileTest.file?(outfile)
out = []
coords.each_with_index do |(y0, y1), idx|
i, l, r = nil
i = "#{page}-#{col}-#{idx}.png"
unless FileTest.file?(i)
system(*["convert", "Goethe-Zertifikat_B1_Wortliste-#{page}.png",
"-crop", "#{x2-x0}x#{y1-y0}+#{x0}+#{y+y0}", "+repage", i])
end
IO.popen(["pdftotext", "-f", page, "-l", page, "-r", 300,
"-x", x0, "-y", y+y0, "-W", x1-x0, "-H", y1-y0,
pdf, "-"].map(&:to_s), 'r') do |f|
l = f.read.strip
end
IO.popen(["pdftotext", "-f", page, "-l", page, "-r", 300,
"-x", x1, "-y", y+y0, "-W", x2-x1, "-H", y1-y0,
pdf, "-"].map(&:to_s), 'r') do |f|
r = f.read.strip
end
# Some fix-ups elided ...
out << [i, l, r]
end
File.open(outfile, "w") { |f| Marshal.dump(out, f) }
The output are marshalled arrays containing [image, def, example]:
$ ruby -e 'require "pp"; pp Marshal.load(File.read("016-l.msh"))[0,5]'
[["016-l-0.png", "A", ""],
["016-l-1.png",
"ab",
"1. Die Fahrt kostet ab Hamburg\n" +
"200 Euro.\n" +
"2. Ab nächster Woche bleibt unser\n" +
"Geschäft samstags geschlossen.\n" +
"3. Mein Bruder besucht uns ab und zu."],
["016-l-2.png",
"abbiegen, biegt ab,\n" + "bog ab, ist abgebogen",
"An der nächsten Kreuzung müssen Sie\n" + "links abbiegen."],
["016-l-3.png",
"die Abbildung, -en",
"Auf der Abbildung sehen Sie, wie man\n" + "das Gerät einschaltet."],
["016-l-4.png",
"das Abenteuer, -",
"1. Unser Urlaub war ein tolles Abenteuer.\n" +
"2. Die Kinder lieben Abenteuergeschichten."]]
The “only” issue now is to generate some useful output from it, yes?
As a foreshadowing – almost. Except for corner cases.
I’ll just generate useful output out of it now
The generation would be almost too easy, if it weren’t for a couple of pesky issues:
- The text extraction sometimes damaged lists – first spat out the bullets, then the text.
- Since the columns were narrow, there were newlines all over the place.
- Some examples with lists crossed column or page boundaries
pdftotextconsidered dash (-) at the end of line as a word break, even when it made no sense.- Some pages did not have sufficient whitespace between entries, thus they
ended up merged together (hence
breaksindetect-breaks.rb).
Long story short, I spent about the same time afterwards running cleanup jobs. Manually inserting section breaks between terms4. And then also things like:
# fix up newlines in examples
if e =~ /\A(\d+)\./
start = $1.to_i
# list
e = e.split(/\d+\.\s*/)[1..-1].map { |x| x.strip.tr("\n", " ") }.
inject([[], start]) { |(o,i),x| [o + ["#{i}. #{x}"], i+1] }.
first.join("\n")
else
# sentence
e = e.tr("\n", " ")
end
But I’ll skip these, as the post is getting too long, and most of it is just heavy context-dependent regexp use.
I’ll say this, though: This is where the diff driven development comes from.
Diff driven development
When I wrote the first version of generate.rb, I made it output both csv
and html, because that’s what I wanted at the end.
Little did I know that checking the resulting output files to git makes for an excellent debugging tool.
You essentially hack on the generator, and periodically use
ruby generate.rb 016; git diff 016.csv to see what’s what.
Prior commit, running the generate on the entire set of pages allows for rather fine testing whether the change was useful.
So, just like TDD uses
tests, DDD uses diff. ;)
Final form of generate.rb & sample output
If you’re following along, you might be interested in the final form of
generate.rb as well as in final output.
The script is rather unwieldy, and as such, you can find generate.rb in my goethe-b1-wortliste GitHub repo.
The resulting output for page 16: csv, html.
Solution
So maybe you only came here for the goods?
Here it is:
(Note: It was last updated 2024-10-28, to fix some last issues with improper formatting that I forgot to push here – diff of the output)
Please heed the disclaimer:
All of it is extracted from Goethe-Zertifikat_B1_Wortliste.pdf (© 2016 Goethe-Institut und ÖSD) because their PDF was unusable for making flashcards.
It is highly likely you can use this for personal purposes, but I make no claim that I own the resulting data. In other words: if I were you, I wouldn’t go using this in any commercial capacity.
Closing words
Obviously I wouldn’t object to you dropping me an email telling me what you think of it. Or pointing out errors I might have missed5.
Updated 2023-12-11: Also, my friend Izi told me about pdftotext -layout
which tries to conserve layout. I think it’s fantastic for general cases (Izi
uses it to extract some credit card statement data), but in this case would
introduce another problem – hyphenated words would remain so6.
-
For the better part of a decade, that is. ↩
-
There! I coined it. ↩
-
Maybe I suck at searching? In which case, teach me to do better, pls? ↩
-
Easiest way: open the
016-annot.pngin gimp, crop the image from the top red rectangle to the height where you want to place break, read off the image height (say, 118), stick it asbreaks['016-l'] = Set.new([118]), re-run page generation, inspect the016-annot.pngif the change took. ↩ -
Because I did not comb over every single definition just yet. ↩
-
But, since I re-ran the extraction with
-layout(for Science™), I also discovered some more cosmetic issues. Hooray for DDD! And thanks, Izi. ;) ↩